این مقاله ششمین مقاله از سری مقالات مربوط به آموزش کتابخانه Microsoft Enterprise Library
5 می باشد. با توجه به پیوستگی و ترتیب مقالات، پیشنهاد می شود که حتما قسمت های قبلی
را ابتدا مطالعه نمایید.
قسمت های قبلی:
-
آموزش کتابخانه Microsoft Enterprise Library 5.0 - قسمت اول
-
آموزش کتابخانه Microsoft Enterprise Library 5.0 - قسمت دوم
-
آموزش کتابخانه Microsoft Enterprise Library 5.0 - قسمت سوم
-
آموزش کتابخانه Microsoft Enterprise Library 5.0 - قسمت چهارم
-
آموزش کتابخانه Microsoft Enterprise Library 5.0 - قسمت پنجم
مقدمه:
در این مقاله قصد داریم به معرفی امکانات بلاک خطا و استثناء (Exception Handling Application Block)
بپردازیم. قبل از اینکه به سراغ این بلاک برویم بهتر است کمی در مورد مدیریت خطا و استثناء
در نرم افزار صحبت کنیم.
مدیریت خطا و استثناء یکی از مهمترین ملاحظاتی است که معمولا در ابتدای طراحی نرم
افزار، توسعه گران را درگیر خود می نماید. در نرم افزار های متوسط و بزرگ در صورتی
که این عمل به درستی انجام نشده باشد می توان آینده ای پر درد سر و پر هزینه برای همه
دست اندرکاران پروژه پیشبینی نمود.
اصولا انسان موجودی جایزالخطا بوده و در نتیجه هرگز نرم افزاری در مقیاس متوسط و
بزرگی تولید نخواهد شد که عاری از باگ و خطا باشد. البته به وجود آمدن این خطاها ممکن
است لزوما مرتبط با خطای برنامه نویس یا طراح نباشد. به طور مثال از کار افتادن سرور
پایگاه داده یا از کار افتادن شبکه ای که برنامه در آن فعال می باشد یا مشکلات سخت
افزاری و ... همگی از مواردی هستند که می توانند باعث ایجاد خطا و استثناء در برنامه
شوند.
با اینکه برنامه نویس مسبب به وجود آمدن اینگونه خطاها نمی باشد ولی به هر حال باید
فکری برای مدیریت اینگونه وقایع نماید تا اینکه اولا در اولین فرصت به رفع نمودن مشکل
مربوطه اقدام نموده و ثانیا کاربر سیستم را از مواجه نمودن با تجربه ای بسیار بد رها
سازد.
نقص در پیاده سازی یک استراتژی مناسب می تواند باعث اتفاقات خیلی ناگوارتری نیز
گردد. به طور مثال رخ دادن یک خطای امنیتی می تواند به فاش شدن اطلاعات بسیار حساس
مانند رمز عبور کاربر یا رشته اتصال پایگاه داده منجر گردد!
مدیریت خطا و اسنثناء مطمئنا هیجان انگیزترین قسمت ساخت یک نرم افزار نیست! ولی
اگر در طراحی این قسمت دقت کافی انجام نشود مطمئنا روز های بسیار بدتری نیز در پیش
رو خواهد بود. بنابراین طراحی یک استراتژی مناسب با توجه به نوع و نیاز نرم افزار از
مهمترین ملاحظات پروژه می باشد.
کلمه "استراتژی" را ما عمدا به کار برده ایم. طراح نرم افزار
باید با توجه به بسیاری از ملاحظات و نیاز ها و محدودیت ها و ... برنامه شروع به تدوین
یک استراتژی برای مدیریت خطاها نماید. در پروژه های متوسط و بزرگ معمولا برنمه نویسان
و طراحان به شکل مستقیم با کاربران نهایی در ارتباط نیستند و در نتیجه باید به گونه
ای خطاها را مدیریت نمود که هر کدام از دینفعان برنامه از قبیل کاربر نهایی، تیم پشتیبانی
نرم افزار، تیم تست و آزمایش نرم افزار و ... وقتی با خطایی مواجه شدند با پیام هایی
مناسب خود روبرو شده و در یک چرخه از پیش تعیین شده، خطای رخ داده شناسایی شده و جهت
رفع آن اقدام گردد.
بیایید کمی فنی تر در این مورد بحث کنیم. فرض کنید پروژه ای داریم که دارای چهار
لایه Data، Business ، UI ، Service می باشد.
اکنون چند سوال مطرح می کنم و از شما خواهش می کنم پس از خواندن سوال ها و قبل از
خواندن ادامه مقاله اندکی در مورد آن ها فکر کنید.
فرض کنید خطایی در لایه Data به وجود آمده است! اکنون چه باید کرد؟ جواب های ممکن:
- باید خطا را در همین لایه مدیریت کرد و از ارسال آن به لایه های بالاتر مانند
Business خودداری کرد.
- باید خطا را بدون هیچ تغییری به لایه های بالاتر جهت مدیریت کردن، ارسال کرد.
- باید خطا را مدیریت نمود و به لایه هایی بالایی نیز رخداد آن را خبر داد.
- باید عین خطای به وجود آمده را به کاربر نمایش داد
- باید خطای به وجود آمده را تغییر داد و با یک پیغام کاربر پسند تر به کاربر
نمایش داد.
- بستگی به نوع خطا دارد و ممکن است برای انواع مختلف خطا و محل به وجود آمده
آن سیاست های مختلفی را در نظر داشته باشیم.
- ....
در حقیقت جواب مطلقا درستی را نمی توان به سوال بالا داد و با توجه به تجربه طراح
و نیاز ها و محدودیت های نرم افزار و بسیار عوامل دیگر باید یک استراتژی مناسب برای
برنامه طراحی نمود. البته برای مدیریت خطا و استثناء در برنامه، الگوهایی (Patterns)
نیز موجود می باشند که در آینده به بررسی آن ها خواهیم پرداخت.
در این مقاله علاوه بر آموزش بلاک خطا و استثناء، ایده هایی را نیز مطرح می کنیم
ولی فراموش نکنید که در نهایت شما هستید که باید استراتژی مورد نظر خود را طراحی کنید.
همانند سایر بلاک های کتابخانه Enterprise Library، پیکر بندی بلاک خطا و استثنا
نیز در فایل پیکربندی (app.config یا web.config) انجام می شود و تنظیمات مختلف از
این فایل ها خوانده می شود
اکنون به سراغ امکانات این بلاک می رویم.
آغاز:
همانند سایر بلاک هایی که تاکنون مورد بررسی قرار گرفته اند مراحل زیر را به ترتیب
جهت استفاده از امکانات این بلاک انجام دهیم:
- افزودن ارجاع اسمبلی های مورد نیاز به برنامه
- اعمال تنظیمات مربوطه در فایل پیکربندی
- افزودن فضاهای نامی مورد نیاز به کلاس ها و نوشتن چند خط کد
جهت استفاده از امکانات پایه و اصلی این بلاک باید سه اسمبلی زیر را به پروژه اضافه
کنیم
- Microsoft.Practices.EnterpriseLibrary.Common.dll
- Microsoft.Practices.ServiceLocation.dll
- Microsoft.Practices.EnterpriseLibrary.ExceptionHandling.dll
در صورتی که بخواهیم خطای رخ داده را لاگ کنیم (از امکانات بلاک لاگ استفاده
کنیم) باید اسمبلی زیر را به پروژه اضافه
کنیم.
- Microsoft.Practices.EnterpriseLibrary.ExceptionHandling.Logging.dll
و در صورتی که بخواهیم خطای مربوطه را در پایگاه داده لاگ کنیم، باید اسمبلی زیر
را نیز به پروژه اضافه کنیم.
- Microsoft.Practices.EnterpriseLibrary.Data.dll
خوب، اکنون فایل پیکربندی را با استفاده از ویرایشگر Enterprise Library v5 Configuration
باز کنید (برای انجام این کار می توانید روی فایل پیکربندی کلیک راست نموده و Edit
Enterprise Library v5 Configuration را انتخاب کنید).
از منوی Blocks گزینه Add Exception Handling Settings را انتخاب کنید.
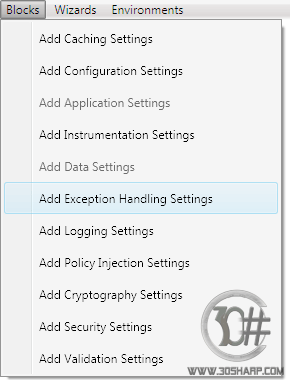
پس از انتخاب این گزینه تنظیماتی مشابه شکل زیر برای شما پدیدار خواهند شد.
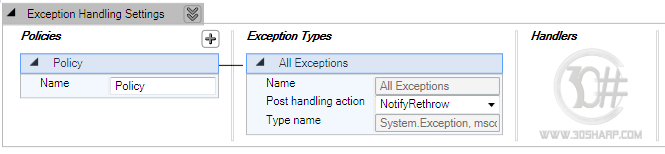
همانگونه که ملاحظه می کنید، تنظیمات بلاک خطا و استثنا از 3 قسمت مهم تشکلی شده
اند:
1. Policy: در این قسمت نامی دلخواه که نشان دهنده سیاستی است
که قصد داریم از آن جهت مدیریت خطاها استفاده کنیم، قرار می گیرد. به طور پیشفرض یک
سیاست به نام Policy توسط ویرایشگر ایجاد شده است. شما می توانید با در نظر گرفتن استراتژی
خود برای مدیریت انواع خطاهای به وجود آمده، سیاست های مختلفی را ایجاد نمایید. به
طور مثال نام هایی از قبیل DataAcceePolicy ، BusinessLayerPolicy، BusinessLayerSecurityPolicy
و غیره شاید نام هایی َآشنا برای شما باشند. برای ایجاد نام های جدید کافیست که روی
علامت "+" کنار قسمت Policy
کلیک نموده و گزینه Add Policy را انتخاب نمایید.
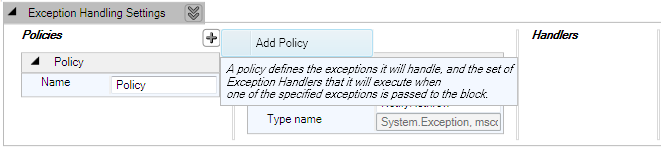
2. Exception Types: بعد از اینکه نام سیاست را تعیین کردیم باید
نوع خطا یا خطاهای مورد نظر خود را که قصد داریم با این سیاست مدیریت کنیم و چگونگی
آن را مشخص کنیم. این عمل در قسمت Exception Types مشخص می گردد. پس از ایجاد یک Policy
به شکل خودکار یک Exception Type به نام All Exceptions به فایل پیکربندی اضافه می
شود که در شکل زیر آن را ملاحظه می کنید. هر Exception type دارای سه بخش به عناوین
Name، Post handling action و Type Name می باشد که در ادامه به معرفی آن ها خواهیم
پرداخت.
فرض کنید قصد داریم سیاستی به نام DataAccessPolicy
ایجاد کنیم و خطاهایی از نوع DBConcurrencyException و DuplicateNameException و NoNullAllowedException
و ... را در لایه Data با آن مدیریت کنیم. برای انجام این کار ابتدا همانطور که قبلا
شرح داده شد روی علامت "+"
کنار قسمت Policy کلیک نموده و نام DataAccessPolicy را وارد نمایید. اکنون همانند
شکل زیر روی منتهی الیه سمت راست بخش DataAccessPolicy کلیک نموده و گزینه Add Exception
Type را انتخاب نمایید.
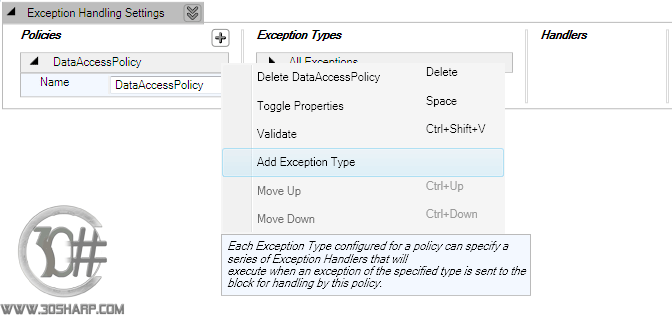
پس از انتخاب این گزینه، پنجره ای باز می شود که باید نوع خطای استثناء مورد نظر
خود را انتخاب کنیم. در شکل زیر ما خطای DBConcurrencyException را انتخاب کرده
ایم.
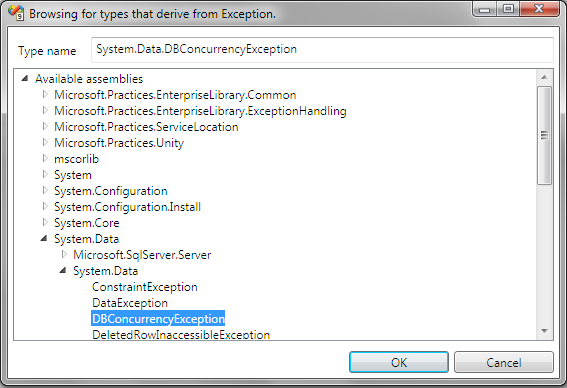
با تایید پنجره فوق، خطای استثناء مورد نظر ما به قسمت Exception Types اضافه می
شود. اگر این عمل را برای خطاهای دیگر از جمله DuplicateNameException و NoNullAllowedException
تکرار کنیم، در نهایت با تصویری مشابه شکل زیر روبرو می شویم.
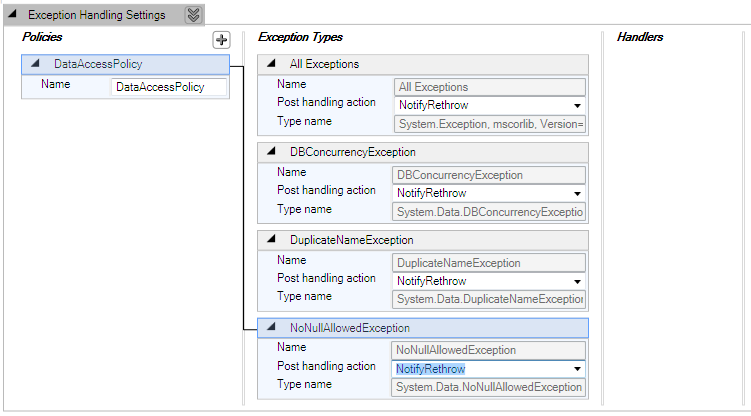
خوب، تا اینجای کار ما سیاستی به نام DataAccessPolicy ایجاد نموده ایم که سه خطای
DBConcurrencyException و DuplicateNameException و NoNullAllowedException را به شکل
ویژه ای قرار است مدیریت کند و سایر انواع خطاهای احتمالی را هم در این سیاست با استفاده
از نوع استثناء All Exceptions می توانیم مدیریت کنیم.
در ابتدای مقاله سوالی را مطرح نمودیم مبنی بر اینکه اگر خطایی در لایه Data به
وجود آمد آِیا باید این خطا به لایه های بالاتر انتقال پیدا کند یا خیر! خصوصیت
Post
handling action برای مشخص نمودن همین مسئله به وجود آمده است. این خصوصیت می تواند
دارای یکی از سه مقدار زیر باشد:
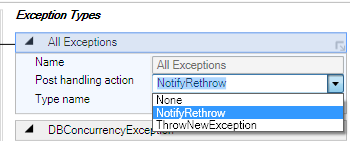
- None: اگر این مقدار را به خصوصیت نسبت دهیم، از طریق کد
و در محل به وجود آمدن خطا می توانیم متوجه شویم که نیازی به ارسال خطا این نوع
خطا به لایه های بالاتر نیست.
- NotifyRethrow: اگر این مقدار را به خصوصیت نسبت دهیم، از
طریق کد و در محل به وجود آمدن خطا می توانیم متوجه شویم که نیاز است که این
نوع خطا را به لایه های بالاتر نیز ارسال کنیم و خطای اصلی بدون تغییر
به لایه های بالاتر ارسال می شود.
- ThrowNewException: اگر این مقدار را به خصوصیت نسبت
دهیم، دیگر نیاز به به چک کردن جهت ارسال خطا به لایه های بالاتر نیست و این
عمل به شکل خودکار و اجباری انجام می شود. در این روش این خطا توسط بلاک
استثناء ایجاد و throw می شود. استفاده از این خصوصیت معمولا توصیه می
شود.
سه مورد فوق را در آینده با مثال توضیح خواهیم داد.
3. Handlers: تاکنون در دو قسمت قبلی مشخص کردیم که چگونه یک سیاست
(Policy) ایجاد نموده و خطاهایی را که قصد داریم آن ها را در این سیاست مدیریت نماییم،
مشخص کنیم. اما اینکه هنگام بروز اینگونه خطا ها چه اتفاقی باید بیفتد و چگونه هر کدام
از این نوع خطاها باید مدیریت شوند را در قسمت Handlers مشخص می کنیم.
Handler ها یا به عبارت کاملتر Exception Handler ها در حقیقت کلاس های هستند که
اینترفیسی به نام IExceptionHandler را پیاده سازی نموده اند. به طور پیشفرض چهار Handler
در بلاک استثناء وجود دارند و البته ما می توانیم در صورت نیاز Handler های دیگری را
نیز به طور سفارشی برای خود بنویسیم.
اکنون به معرفی این Handler ها می پردازیم:
- Logging Handler: این هندلر جهت لاگ نمودن خطا استفاده می
شود. در مقاله قبلی به تفصیل به معرفی بلاک لاگ پرداختیم. با استفاده از بلاگ لاگ
و این هندلر می توانیم خطاها را در محل های مختلف ذخیره کنیم تا در آینده بتوانیم
به بررسی دقیق جزئیات خطاهای به وجود آمده بپردازیم. پس هر زمان نیاز داشته باشیم
که خطا را ذخیره کنیم از این هندلر استفاده می کنیم. لازم به ذکر است که برای هر
خطا می توان از یک یا مجموعه ای از هندلر ها استفاده نمود. به لاگ نمودن متن خطا
که قسمتی از مدیرت خطا و استثناء می باشد الگوی لاگ نمودن استثناء (Exception Logging
Pattern) گفته می شود.
- Wrap Handler: گاهی اوقات خطای (استثناء) اصلی رخ داده در
برنامه دارای پیام بامعنی یا کاربر پسندی نیست. با استفاده از این هندلر یک خطای
استثناء جدید ایجاد شده و اطلاعات معنی دار بدان اضافه می گردد. سپس در خصوصیت
InnerException خطای جدید، خطای اصلی را قرار می گیرد. در نتیجه ما یک خطای اسثناء
جدید خواهیم داشت که حاوی خطای اصلی به علاوه اطلاعات اضافه شده توسط ما می باشد.
معمولا هنگام رخ دادن خطای اصلی ابتدا آن را با استفاده از هندلر Logging Handler
لاگ نموده و سپس با استفاده از هندلر Wrap Handler پوشانیده و به سمت لایه
های بالا تر ارسال می کنیم. به این روش اصطلاحا الگوی ترجمه خطا (Exception Translation
Pattern) گفته می شود. در ادامه مقاله کاربرد این هندلر ها را در عمل ملاحظه خواهید
نمود.
- Replace Handler: همانطور که از نام این هندلر نمایان است،
این هندلر جهت جایگزین نمودن خطای اصلی با یک خطای جدید که ما مشخصات آن را تعیین
می کنیم به وجود آمده است. بیشترین استفاده این هندلر در هنگام رخ دادن خطاهای
امنیتی می باشد. خطای تولید شده می تواند دارای اطلاعات بسیار حساسی باشد و نباید
این خطا به لایه های بالاتر نفوذ کند. بنابراین معمولا ابتدا خطای به وجود آمده
را با استفاده از هندلر Logging Handler لاگ نموده و سپس با استفاده از هندلر Replace
Handler آن را با یک خطای کاربر پسند جایگزین نموده و به سمت لایه های بالاتر یا
برای نمایش به کاربر ارسال می کنیم. به این روش اصطلاحا الگوی محافظت از خطا (Exception
Shielding Pattern) گفته می شود. در ادامه مقاله کاربرد این هندلر ها را در عمل
ملاحظه خواهید نمود.
- WCF Fault Contract Exception Handler: با استفاده از این
هندلر در سرویس های WCF می توانیم یک Fault Contract پیکربندی شده را هنگام ایجاد
خطا تولید نموده و به سمت کلاینت ارسال کنیم. مثالی در این مورد را در آینده بررسی
خواهیم نمود.
- Custom Exception Handler: اگر هیچکدام از هندلر هایی که
تاکنون معرفی نمودیم نیاز شما را رفع نکردند، شما می توانید هندلر مورد نظر خود
را بنویسید. به طور مثال ممکن است تمایل داشته باشید یک هندلر بنویسید که خطای
به وجود آمده را در قالب یک MessageBox به کاربر نمایش دهد (این هندلر در سورس
همراه مقاله پیاده سازی شده است).
تاکنون فرا گرفتیم که هر کدام از خطاهای مشخص شده در قسمت Exception Types می توانند
دارای یک یا چند هندلر باشند. اکنون مثالی که شروع کردیم را کاملتر می کنیم. فرض کنید
که می خواهیم در هنگام استفاده از سیاست DataAccessPolicy و زمانی که خطایی از نوع
DBConcurrencyException رخ می دهد، ابتدا متن خطا را به شکل کامل لاگ کنیم و سپس خطای
مربوطه را با استفاده از هندلر Wrap Handler تبدیل به یک خطا با پیام مناسب نموده و
به لایه ها بالاتر ارسال کنیم. بدین منظور باید ابتدا هندلر Logging را به خطای DBConcurrencyException
اضافه کنیم.
برای انجام این کار بر روی منتهی الیه سمت راست DBConcurrencyException مطابق شکل
زیر کلیک نموده و از میان هندلر ها، گزینه Add Logging Exception Handler را انتخاب
کنید.
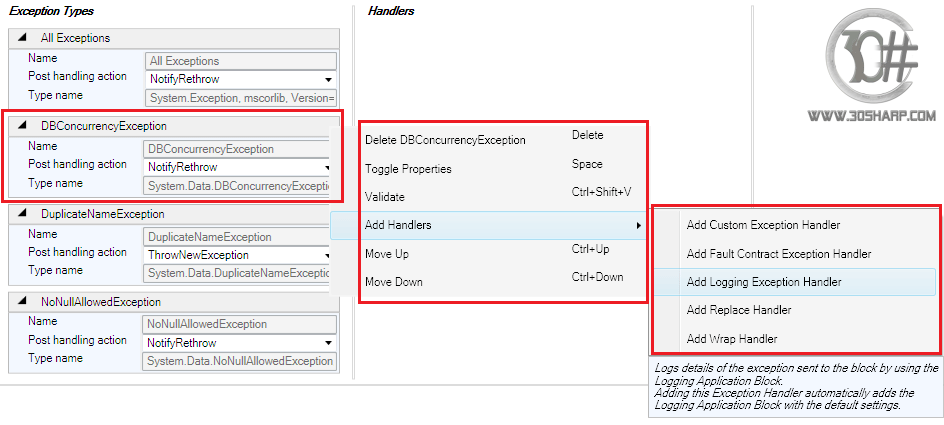
اکنون هندلر لاگ به شکل زیر به وجود آمده و ضمنا قسمت تنظیمات بلاک لاگ نیز به فایل
پیکربندی اضافه می گردد (برای چندمین بار تاکید می کنم که در مقاله قبلی به تفصیل در
مورد بلاک لاگ و تنظیمات مربوطه بحث کردیم).
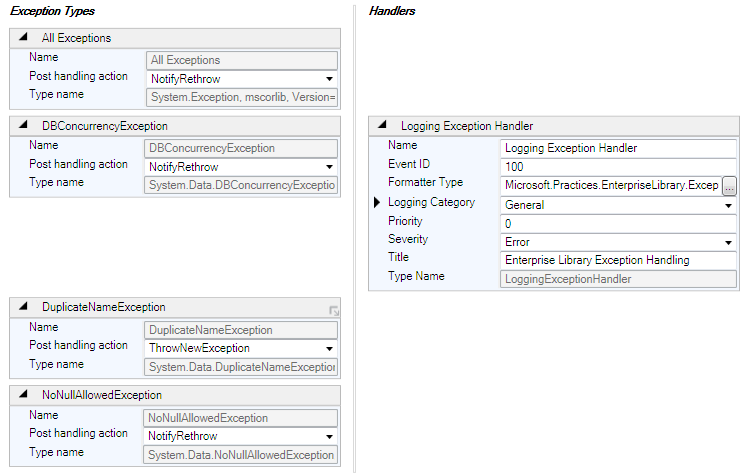
خصوصیات هندلر Logging Exception Handler برای افرادی که با بلاک لاگ آشنا هستند
کاملا گویا هستند. اکنون قصد داریم این خطا را با استفاده از هندلر Wrap Handler بپوشانیم
و خطای جدیدی ایجاد نماییم که دارای پیغام مناسبتری باشد. برای انجام اینکار همانند
دفعه قبل عمل نموده ولی اینبار گزینه Add Wrap Handler را انتخاب کنید.
تذکر:
توجه داشته باشید که ترتیب اضافه کردن هندلر ها اهمیت زیادی دارد. به طوری که هر
هندلر با نتیجه به دست آمده از هندلر قبلی کار می کند. بنابراین معمولا ابتدا هندلر
لاگ استفاده می شود تا محتوای خطای اصلی لاگ شود و سپس هندلر های بعدی شروع به اعمال
تغییرات روی خطای اصلی می کنند.
شکل زیر پس از افزودن هندلر Wrap نمایان می گردد.
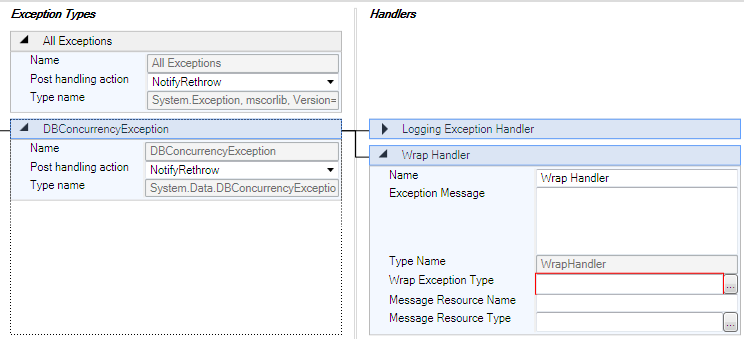
همانگونه که ملاحظه می کنید هندلر Wrap زیر هندلر لاگ اضافه شد و هر دو متعلق به
خطای DBConcurrencyException در سیاست DataAccessPolicy هستند.
هندلر Wrap دارای خصوصیاتی می باشد که اکنون به معرفی آن ها می پردازیم.
- Name: یک نام دلخواه برای این هندلر بوده که قابل تغییر توسط
شما می باشد
- Exception Massage: پیام جدیدی است که ما قصد داریم در قسمت
Message خطای جدید، به جای متن اصلی خطا قرار گیرد
- Wrap Exception Type: نوع خطای جدید را می توانیم با استفاده
از این خصوصیت تعیین کنیم. خطای جدید را می توان از نوع خطاهای موجود در پلتفرم
دات نت انتخاب نمود یا از نوع خطای سفارشی نوشته شده توسط شما (مثلا به نام MyUserFriendlyException).
- Type Name: این خصوصیت به شکل فقط خواندنی (Read Only) بوده
و نوع هندلر را مشخص می کند.
- Resource Name & Resource Type: در خصوصیت Message ملاحظه
کردید که ما می توانیم پیامی دلخواه را به این خصوصیت نسبت دهیم. اما با استفاده
از این دو خصوصیت می توان این پیام را از درون یک فایل Resource بیرون بکشیم و
بنابراین پیام را به شکل بومی شده (Localized) و به زبان محلی برنامه در خصوصیت
Message اعمال کنیم. برای انجام این کار باید نام و نوع Resource را در این دو
خصوصیت ست کنید.
افزودن هندلر Replace Handler نیز دقیقا مشابه Wrap Handler می باشد. برای
انجام اینکار همانند دفعه قبل عمل نموده ولی اینبار گزینه Add Replace Handler را انتخاب
کنید.
خوب، تاکنون هر چه گفتیم مربوط به فایل پیکربندی و تنظیمات بود. اکنون به سراغ کد
رفته و از تنظیمات انجام شده استفاده خواهیم نمود.
برنامه نویسی برای بلاک مدیریت خطا و استثناء:
تا قبل از ارائه نسخه 5 کتابخانه Enterprise Library از کلاس ExceptionPolicy جهت
مدیریت خطا و استثناء استفاده می شد. البته این کلاس جهت سازگاری با نسخه های قبلی
همچنان در کتابخانه موجود بوده و قابل استفاده می باشد ولی استفاده از آن توصیه نمی
شود.
در کتابخانه Enterprise Library 5 کلاسی به نام ExceptionManager معرفی شده است
که از امکانات این کلاس استفاده خواهیم نمود. این کلاس دارای دو متد به نام های Process
و HandleException می باشد که جهت مدیریت خطا استفاده می شوند. با توجه به محدودیت
هایی که در استفاده از متد Process وجود دارد، ما در مورد این متد بحث نخواهیم کرد
و در عوض به بررسی متد HandleException خواهیم پرداخت.
اکنون قصد داریم ادامه مقاله را با یک مثال پیش ببریم ولی قبل از آن لطفا به
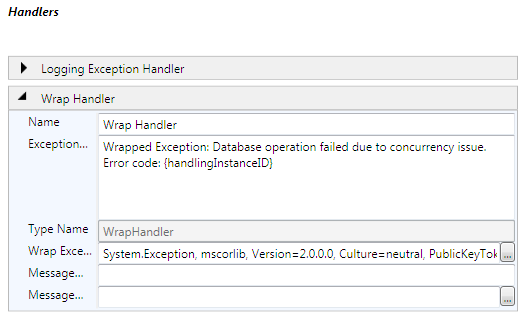
خصوصیت Message هندلر Wrap که در بخش قبلی ایجاد کردیم پیام زیر را نسبت دهید.
Wrapped Exception: Database operation failed due to concurrency issue.
Error code: {handlingInstanceID}
در نتیجه شکل زیر پدید می آید.
در مورد توکن {handlingInstanceID} که در بخش Message قرار
داده ایم، در آینده صحبت می کنیم.
به قطعه کد زیر دقت کنید.
public
void MathodInUIlayer()
{
try
{
MethodInDataLayer();
}
catch
(Exception ex)
{
//
Handling error in UI layer
}
}
public
void MethodInDataLayer()
{
try
{
throw
new DBConcurrencyException("Original
Exception: Concurrency violation...");
}
catch
(DBConcurrencyException concurrencyException)
{
// Handling error in data
layer
ExceptionManager
exManager = EnterpriseLibraryContainer.Current.GetInstance<ExceptionManager>();
if (exManager.HandleException(concurrencyException,
"DataAccessPolicy"))
throw;
}
}
در قطعه کد بالا دو متد نوشته شده است. اولین متد به نام MathodInUIlayer
در لایه UI برنامه قرار دارد و وظیفه آن فراخوانی متد MethodInDataLayer در لایه
Data می باشد که قطعه کد اصلی ما نوشته شده است.
در متد MethodInDataLayer یک خطا از نوع DBConcurrencyException تولید کرده ایم
و در قسمت catch به مدیریت آن پرداخته ایم. ابتدا طبق روال متداول کتابخانه
Enterprise Library 5 یک نمونه از کلاس ExceptionManager ایجاد نموده ایم.
اما قسمت جالب داستان از اینجا شروع می شود. متد HandleException را فراخوانی
نموده و خطای اصلی به وجود آمده را به همراه نام Policy مورد نظر خودمان به این متد
ارسال کرده ایم. طبق پیکربندی این سیاست در این مقاله متد HandleException شروع به
اجرای تمامی هندلر های ایجاد شده برای خطای DBConcurrencyException در سیاست
DataAccessPolicy نموده و یک مقدار منطقی (bool) را بر می گرداند. اما این مقدار
منطقی چیست؟
قبلا در این مقاله به معرفی خصوصیت Post handling action مربوط به هر نوع خطا و
مقادیری که می تواند بگیرد یعنی None، NotifyRethrow، ThrowNewException پرداخته
ایم. در صورتی که مقدار None به این خصوصیت نسبت داده شده باشد، مقدار برگشتی متد HandleException برابر
false می باشد و بنابراین کار مدیریت خطا به پایان رسیده و
خطا به لایه های بالاتر ارسال نمی شود (یعنی شرط if اجرا نشده و در نتیجه فرمان
throw انجام نمی شود). اما اگر مقدار NotifyRethrow نسبت داده شده باشد،
مقدار برگشتی true بوده و نتیجه شرط مثبت بوده و فرمان
throw انجام می شود
و بنابراین خطا به متد MathodInUIlayer منتقل شده و در قسمت
catch این متد می توان
خطای Wrap شده را مشاهده نمود.
تذکرات بسیار مهم:
- اگر قصد دارید از هندلر های Wrap و Replace استفاده کنید حتما از
ThrowNewException در خصوصیت Post handling action خطا استفاده کنید. به طور کلی
این خصوصیت پرکاربرد ترین می باشد.
- دقت کنید که پس از چک کردن مقدار برگشتی تابع HandleException همیشه از
فرمان throw استفاده کنید و نه "throw ex". اگر از فرمان "throw ex" استفاده
کنید، قسمت stack trace خطای ما با stack trace جدیدی که در خط فرمان "throw
ex" به وجود می آید، جایگزین خواهد شد که این موضوع معمولا مطلوب ما نمی باشد.
در صورتی که مقدار خصوصیت Post handling action برابر با ThrowNewException
باشد، دیگر نیازی به چک کردن مقدار برگشتی متد HandleException نیست و در هر صورت
پس از اجرای تمامی هندلر ها، فرمان throw از داخل بلاک خطا و استثناء صادر می شود.
اما برای اینکه منطق کد ما به هم نخورد پیشنهاد می شود که همواره مقدار برگشتی متد
HandleException همانند قطعه کد بالا چک شود.
اما اجازه دهید عملکرد قطعه کد بالا را در عمل ببینیم
مشاهده جزئیات خطای concurrencyException در متد MethodInDataLayer قبل
از فراخوانی متد HandleException:
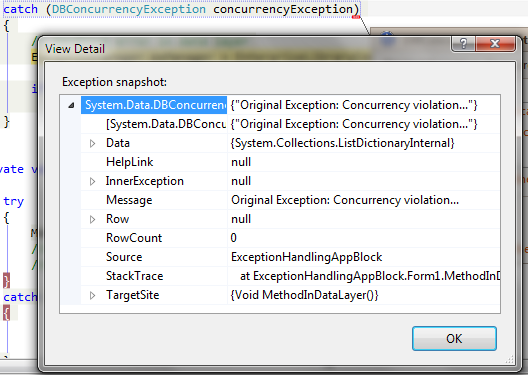
مشاهده جزئیات خطای انتقال داده شده به متد MathodInUIlayer:
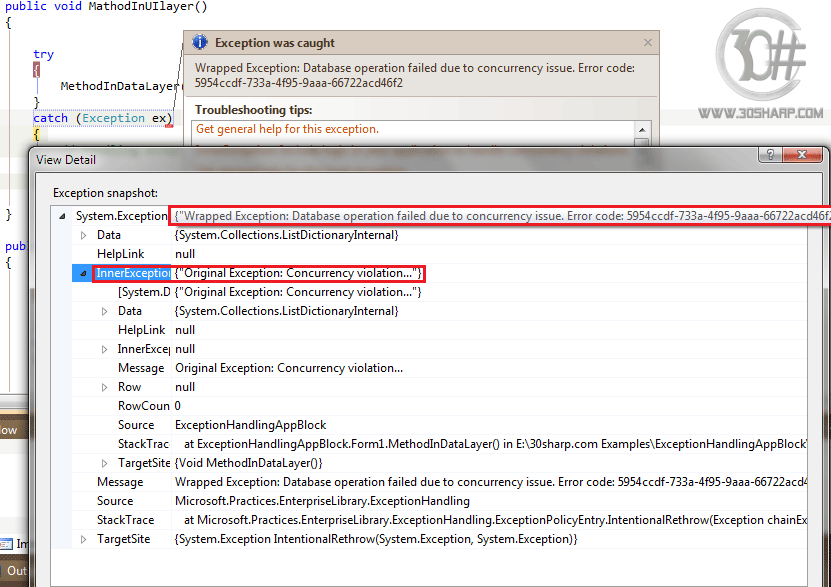
همانگونه که از شکل بالا مشخص می شود و ما هم قبلا اعلام کرده بودیم، هندلر Wrap
یک خطای استثناء جدید ایجاد کرده است و خطای اصلی را به عنوان InnerException به
خطای جدید
نسبت داده است و ضمنا پیامی را که در فایل پیکربندی مشخص کرده ایم به عنوان پیام اصلی خطای جدید نمایش می دهد. با این تفاوت که در قسمت پیام به جای توکن {handlingInstanceID} یک شناسه Guid قرار گرفته است!
قبل از اینکه به معرفی توکن {handlingInstanceID} بپردازیم بهتر است خطای لاگ
شده توسط هندلر لاگ را که در قسمت Event Log ویندوز ذخیره شده است را نیز مشاهده
کنیم.
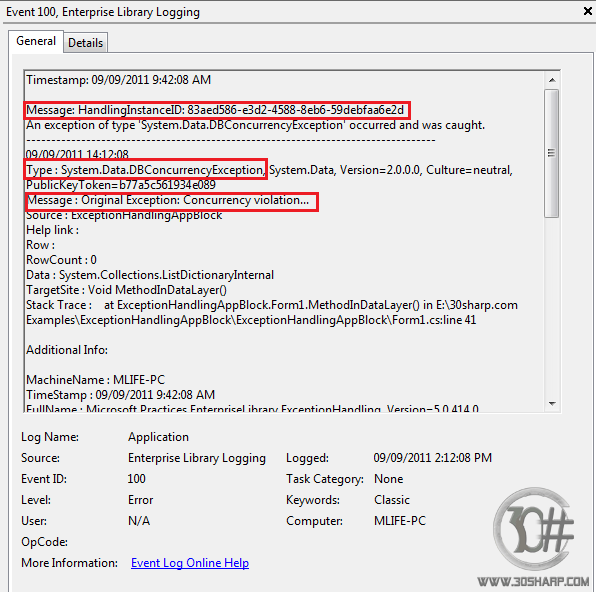
در شکل بالا نیز ملاحظه می کنید که در قسمت Message یک شناسه Guid به نام
HandlingInstanceID موجود می باشد! در حقیقت HandlingInstanceID یک شناسه منحصر به
فرد به ازای هر خطا می باشد که توسط بلاک مدیریت خطا و استثناء تولید می شود. این
شناسه کاربرد جالبی دارد. فرض کنید یک مشتری با شما تماس می گیرد و اعلام می کند که
با خطایی روبرو شده است. شما نیز تمامی خطا ها را لاگ می کنید ولی از کجا می توانید
مطمئن باشید کدام خطای لاگ شده مورد نظر مشتری می باشد؟ راه حل این است که همانند
کاری که ما در بالا انجام دادیم این شناسه را به کاربر به عنوان کد خطا نمایش دهید
تا کاربر در تماس با شما با خواندن یا ایمیل نمودن کد خطا شما را در جهت شناسایی
خطای مربوطه در بین موارد لاگ شده یاری کند.
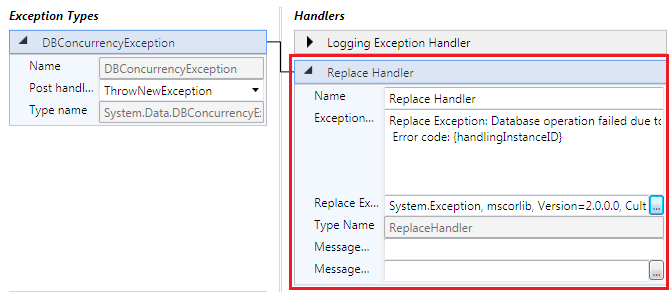
اکنون هندلر Wrap را حذف نموده و در عوض هندلر Replace را اضافه می کنیم
قطعه کد بالا را مجددا اجرا می کنیم و خطای ارسال شده به متد MathodInUIlayer را
بررسی می کنیم.
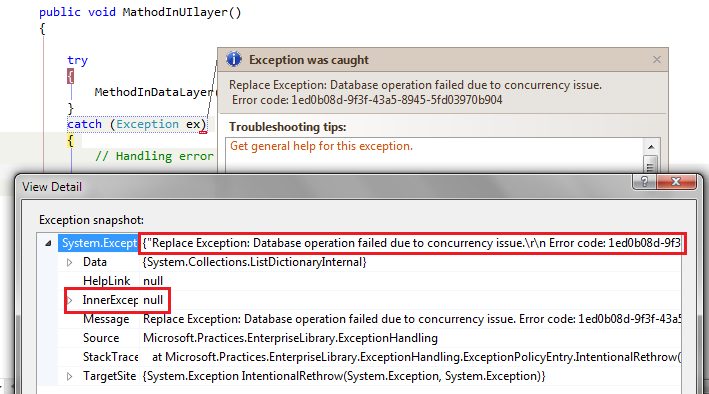
همانطور که می بینید خطای اصلی به این لایه ارسال نشده است و خطایی جدید جایگزین
آن شده است.
تاکنون به بررسی هندلرهای Wrap، Replace، Logging پرداخته ایم. در ادامه مقاله
به بررسی WCF Fault Contract Exception Handler می پردازیم.
بررسی WCF Fault Contract Exception Handler:
تاکنون به بررسی نحوه اداره نمودن خطا در محیط یک برنامه یا یک AppDomain
پرداخته ایم. اما مدیریت خطا در محیط های توزیع شده مقداری متفاوت می باشد. در این
قسمت به بررسی نحوه مدیریت خطا در یک سرویس WCF و ارسال اطلاعات مورد نیاز در مورد
خطا به کلاینت مربوطه می پردازیم. بدیهی است که یادگیری این مبحث نیاز به آشنایی
شما با مفاهیم پایه سرویس های WCF می باشد.
فرض کنید یک برنامه ای در یک رایانه شخصی در حال اجرا می باشد. این برنامه یک
متد از یک سرویس WCF در رایانه ای که هزاران کیلومتر دور تر قرار دارد را فراخوانی
می کند. هنگام اجرای فرامین این متد یک خطا رخ می دهد و اکنون باید برنامه
کلاینت را به نحوی از بروز خطا مطلع نمود و همچنین اطلاعات کافی و مورد نیاز را
برای او جهت پیگیری مسئله فراهم نمود.
اکنون بک پروژه مجزا به منظور لایه Service ایجاد می کنیم و قصد داریم عمل بروز
خطا و استثناء را در آن شبیه سازی کنیم (سناریوی کامل این مبحث از طریق لینک بالای
مقاله قابل دریافت می باشد).
برای مدیریت خطا و استثناء در سرویس های WCF از الگوی محافظت از خطا (Exception
Shielding Pattern) استفاده می کنیم و در ضمن باید اسمبلی زیر را نیز علاوه بر سایر
اسمبلی هایی که قبلا ذکر شدند، به پروژه سرویس اضافه کنیم.
- Microsoft.Practices.EnterpriseLibrary.ExceptionHandling.WCF.dll
همانطور که احتمالا مستحضر هستید برای انتقال خطا از سمت سرویس به سمت کلاینت در
سرویس های WCF از
کلاسی به نام FaultContract استفاده می شود. این کلاس یک DataContract را که حاوی
جزئیات خطای مد نظر ما است را به سمت کلاینت ارسال می کند.
قبل از هرچیزی یک کلاس به نام GenericFaultContract می نویسیم که در هنگام رخ
دادن یک خطا در سرویس، اطلاعاتی شامل کد خطا (همان HandlingInstanceID که قبلا در
مورد آن بحث کردیم) و متنی که شامل توضیحاتی در مورد خطا می باشد را از طریق آن به
سمت کلاینت ارسال کنیم.
[DataContract]
public class GenericFaultContract
{
[DataMember]
public Guid FaultID { get; set; }
[DataMember]
public string FaultMessage { get; set; }
}
در کلاس خصوصیت FaultID کد خطا و خصوصیت FaultMessage توضیحات خطا را برای
کلاینت نگهداری می کند. شما با توجه به نیاز برنامه خود می توانید این
کلاس را برای خود سفارشی سازی کنید.
اکنون به سراغ کلاس سرویس می رویم. در اینترفیس مربوطه متدی به نام GetBlogPost
می نویسیم که قرار است رخداد خطا را در آن شبیه سازی کنیم.
[ServiceContract]
public interface IBlogService
{
[OperationContract]
[FaultContract(typeof(GenericFaultContract))]
BlogPost GetBlogPost(int id);
}
همانطور که ملاحظه می کنید به متد GetBlogPost یک Attribute جدید به نام
FaultContract ایجاد افزوده ایم و در سازنده این کلاس نوع
GenericFaultContract را
ارسال کرده ایم و بدینگونه مشخصی کردیم که هنگام رخداد خطا، یک کلاس از نوع
GenericFaultContract ایجاد شده و توسط کلاس FaultContract به سمت کلاینت ارسال می
شود.
نوبت به پیاده سازی سرویس رسیده است.
[ExceptionShielding("BlogServicePolicy")]
public class BlogService : IBlogService
{
public BlogPost GetBlogPost(int id)
{
//Simulating a security exception to demonstrate exception shielding
// www.30sharp.com
throw new SecurityException("Original Exception: Security exception containing sensitive information.");
}
}
نکته ای که در کلاس بالا مشهود است، اعمال یک Attribute از نوع
ExceptionShielding می باشد که به سازنده آن نام سیاست (Policy) مورد نظر خود (BlogServicePolicy)برای
اداره نمودن خطا را ارسال کرده ایم. این سیاست را در ادامه مقاله در فایل پیکربندی
تعریف می کنیم.
داخل متد GetBlogPost یک خطا از نوع SecurityException ایجاد کرده ایم که حاوی
اطلاعات حساسی است که نباید کلاینت از آن مطلع گردد. دقت کنید که اثری از بلاک
try/catch در قطعه کد بالا نیست!
خوب، اکنون به سراغ فایل پیکربندی سرویس رفته و تنظیمات مورد نظر خود را انجام
می دهیم.
ابتدا یک
سیاست (Policy) به نام BlogServicePolicy ایجاد می کنیم. یک خطا از نوع
Exception به این سیاست اضافه می کنیم و خصوصیت Post handling action را برابر
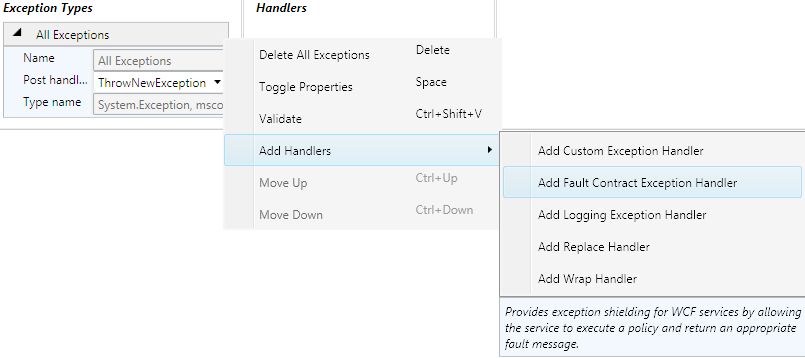
ThrowNewException قرار می دهیم. روی منتهی الیه سمت راست این Exception کلیک
نموده و هندلر Fault Contract Exception Handler را به شکل زیر به فایل پیکربندی
اضافه می کنیم.
اطلاعات هندلر Fault Contract Exception را به شکل زیر تغییر می دهیم.
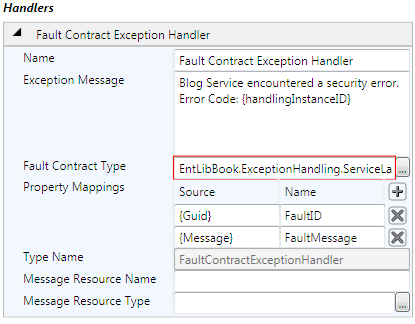
در قسمت زیر به معرفی خصوصیات جدید این هندلر می پردازیم.
- Exception Message: در این قسمت پیامی که قصد داریم هنگام اجرای خطا برای
کاربر ارسال شود را می نویسیم.
- FaultContractType: آدرس کلاس
GenericFaultContract را در
اینجا وارد می کنیم.
- Property Mappings: این خصوصیت جهت نگاشت (مپ) نمودن
خصوصیات خطا با خصوصیات کلاس GenericFaultContract استفاده می شود. همانطور که
می بینید خصوصیات FaultID و FaultMessage با یک شناسه {Guid} و خصوصیت Message
خطا نگاشت شده اند. هنگام رخداد یک خطا این عملیات نگاشت انجام می شود.
سرویس را اجرا نموده و به سراغ کلاینت می رویم. از سمت کلاینت از سرویس رفرنس
گرفته و قطعه کد زیر را می نویسیم.
try
{
ServiceProxy.BlogServiceClient client = new ServiceProxy.BlogServiceClient();
client.GetBlogPost(1);
}
catch (FaultException<ServiceProxy.GenericFaultContract> faultException)
{
MessageBox.Show("FaultID: " + faultException.Detail.FaultID + "\n" +
"Message: " + faultException.Message);
}
هنگام اجرای قطعه کد بالا، خطای سرویس رخ داده و به سمت کلاینت ارسال می شود. در
قسمت catch این خطا گرفتار شده و دیالوگ زیر نمایش داده می شود.
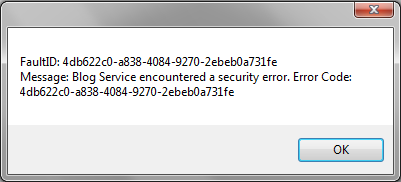
همانطور که ملاحظه می کنید پیام که مورد نظر ما به همراه کد خطا به سمت کلاینت
ارسال شده است.
در این مقاله سعی کردیم به بررسی اجزای اصلی بلاک خطا و استثناء بپردازیم و ضمنا
فرض شده است که مخاطب مقاله دارای تجربه کافی در زمینه برنامه نویسی و تسلط نسبی
روی مفاهیم مهم و به روز پلتفرم .NET می باشد (در غیر اینصورت به جای این مقاله
باید یک کتاب می نوشتیم!). اما سورس همراه مقاله حاوی سناریوهای کاربردی تر می باشد
که بررسی آن جهت درک عمیق مطالب قویا توصیه می شود.
قطعه کد کامل مقاله، شامل سناریوهای کاربردی
تر از طریق لینک بالای صفحه قابل دریافت می باشد.
منابع :
30sharp.com
Microsoft Enterprise Library 5.0
Developer’s Guide to Microsoft Enterprise Library