Referential Integrity یا بطور خلاصه RI را از دو طریق می توانیم پیاده سازی کنیم. 1. DDL و 2. Procedure در مورد اول که بطور نسبتا مفصلی در اینجا به آن پرداختم. ولی اکنون وقت آن فرا رسیده که مورد دوم را بررسی کنیم. یکی از ویژگی هایی که در کلید های خارجی وجود دارد بحث Cascading است. به این معنا که مثلا با حذف رکورد های Parent تمام سطرهای مرتبط در جدول Child نیز حذف می شوند (اگر خاصیت Delete روی Cascade تنظیم شده باشد، در حالت پیشفرض No Action است که مانع از حذف رکورد Parent خواهد شد در زمانی که وجود داشته باشد مقداری در جدول Child که به مقدار در حال حذف شدن کلید جدول Parent ارجاع داده باشد). مثلا با حذف یک دانشجو تمام سطرهای در جدول دروس انتخابی توسط دانشجو که به مقدار کلید جدول دانشجو ارجاع داده شده اند حذف خواهند شد.
فرض کنید دو جدول با نام های Parent به معنای والد و Child به معنای فرزند داریم (از این نام گذاری استفاده کردم تا درک مطالب ساده تر شود). جدول Parent وظیفه ی ذخیره داده های مرتبط به یک کاربر از جمله کد کاربر (user_id) و نام کاربر (user_name) را دارد. و جدول بعدی برای نگهداری نام و کد نویسنده (Author) و همچنین کد کاربر ایجاد کننده سطر و کد تغییر دهنده ی سطر است. این دو کد به جدول Parent ارجاع می دهد. اگر کلید های خارجی برای جدول Child ایجاد کنیم آنگاه دیاگرام آن به شکل زیر خواهد بود:
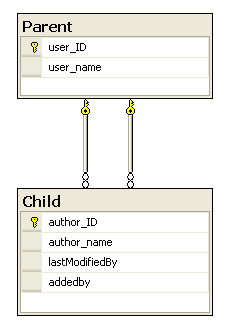
بطور مثال اگر بخواهیم برای هر دو کلید خارجی Delete Rule را Cascade در نظر بگیریم با پیغام multiple cascade paths مواجه خواهید شد. به این معنا که SQL Server نمی تواند این موضوع را پشتیبانی کند. اگر یک سطر از جدول Parent حذف شود SQL Server از دو طریق می تواند داده های جدول Child را تغییر دهد. یکی از طریق کلید خارجی lastModifiedBy و دیگری addedBy.
برای رفع مشکل فوق تنها راه موجود روشهای پروسیجری مثل Stored Procedure و Trigger است. در ادامه پیاده سازی خاصیت Cascade Update را از طریق این روش شرح خواهم داد. ابتدا دو جدول را با کمک DDL (زبان تعریف داده) زیر ایجاد کنید:
توجه داشته باشید که نام کاربری در جدول UNIQUE است.
CREATE TABLE Parent
(user_ID INTEGER NOT NULL PRIMARY KEY,
user_name CHAR(50) NOT NULL
UNIQUE (user_name));
GO
CREATE TABLE Child
(author_ID INTEGER NOT NULL PRIMARY KEY,
author_name CHAR(50) NOT NULL,
lastModifiedBy INTEGER NOT NULL,
addedby INTEGER NOT NULL)
GO
و داده های آزمایشی زیر را در دو جدول انتشار دهید:
INSERT INTO Parent
VALUES (1, 'user_1'),
(2, 'user_2');
INSERT INTO Child
VALUES (1, 'author_1', 1, 2),
(2, 'author_2', 2, 1);
هدف ما ایجاد پروسیجری (یا تریگری) است که بعد از UPDATE کردن سطر از جدول Parent جدول Child نیز بروز رسانی شود.
مثلا اگر user_id های 1 و 2 به ترتیب به 10 و 20 تغییر کنند داده های جدول Child بایستی به شکل زیر در بیاید:
author_id author_name lastModifiedBy addedby
----------- ----------- -------------- -----------
1 author_1 10 20
2 author_2 20 10
اگر تنها یک سطر از جدول Parent حذف شود بسادگی می توانیم تریگر مربوط را ایجاد کنیم با کدی شبیه به کد زیر:
CREATE TRIGGER trg_after_parent
ON Parent
AFTER update AS
BEGIN
UPDATE Child
SET lastModifiedBy = (SELECT user_id FROM inserted)
WHERE lastModifiedBy = (SELECT user_id FROM deleted);
UPDATE Child
SET addedBy = (SELECT user_id FROM inserted)
WHERE addedBy = (SELECT user_id FROM deleted);
END;
ولی ما نمی توانیم از این روش استفاده کنیم چرا که بیشتر مواقع ممکن است بیش از یک کلید اصلی از جدول Parent بروز رسانی شود.
روش صیحیح بکار گیری یک جدول موقت و ماده ی OUTPUT است که در نسخه ی 2005 معرفی شده است.
هنگامی که یک داده بروز رسانی می شود در واقع دو عمل اتفاق افتاده است. حذف سطر و درج سطر.
OUTPUT این قابلیت را به ما می دهد که بتوانیم مقادیر حذف شده و همچنین مقادیر درج شده را در یک جدول درج کنیم یا حتی به عنوان خروجی به نمایش در بیاریم. پس یک جدول موقت با دو ستون با نام های id قدیمی و id جدید تعریف می کنیم تا در عبارت UPDATE سطرهای درج شده و حذف شده را در آن درج کنیم. بعد از این عمل جدول Child را با جدول موقت بر اساس ستون id قدیمی اتصال می دهیم و مقادیر دو ستون خارجی را بر اساس ستون id جدید بروز رسانی می کنیم. یعنی:
IF object_id ('tempdb..#temp_table', 'U') IS NOT NULL DROP TABLE #temp_table
CREATE TABLE #temp_table (old_user_id int, new_user_id int);
UPDATE P
SET user_id = D.user_id
OUTPUT inserted.user_ID AS new_user_id,
deleted.user_ID AS old_user_id
INTO #temp_table (new_user_id, old_user_id)
FROM Parent P
JOIN (SELECT 10, 1
UNION ALL
SELECT 20, 2) AS D(user_id, old)
ON P.user_id = D.old;
UPDATE C
SET lastModifiedBy = T1.new_user_id,
addedBy = T2.new_user_id
FROM Child C
JOIN #temp_table T1
ON C.lastModifiedBy = T1.old_user_id
JOIN #temp_table T2
ON C.addedBy = T2.old_user_id;
در اینجا برای بروز رسانی دو سطر با دو مقدار متفاوت از یک عبارت جدول استفاده کردم. شما می توانید نسبت به نیاز خود عبارت update را customize کنید.
بدلیل اینکه ستون user_name منحصر هست می توانیم از روشی دیگر این کار را انجام دهیم. اگر Update Trigger روی یک جدول تعریف کرده باشیم بعد از هر بروز رسانی دو جدول مجازی inserted و deleted مقدار دهی می شوند. چرا که یک عمل بروز رسانی در واقع یک عمل حذف و یک عمل درج است. اگر مقدار ستون user_id ویرایش شود می توانیم دو جدول مجازی Inserted و Deleted را بر اساس مقدار ستون user_name مچ کنیم تا پی ببریم چه user_id حذف شده و به چه مقداری ویرایش شده است.
در نتیجه با توضیحات مذکور Trigger به شکل زیر در خواهد آمد:
CREATE TRIGGER after_update_parent
ON Parent
AFTER update AS
BEGIN
;WITH Match (old_user_id, new_user_id) AS
(SELECT D.user_id, I.user_id
FROM inserted I
JOIN deleted D
ON I.user_name = D.user_name)
UPDATE C
SET lastModifiedBy = T1.new_user_id,
addedBy = T2.new_user_id
FROM Child C
JOIN Match T1
ON C.lastModifiedBy = T1.old_user_id
JOIN Match T2
ON C.addedBy = T2.old_user_id;
END;