مقدمه
تقسیم رابطه ای (Relational Division) یکی از مساله های جالش انگیز کلاسیک می باشد. که به این پرس و جو به کرات احتیاج پیدا می کنیم. و مشخصه بارز این پرس و جو کلمه ی تمام است. بطور مثال تمام عبارات زیر نوعی تقسیم رابطه می باشند:
"چه دانشجویانی تمام دروس تخصصی خود را گذرانده اند"
"چه کسانی با هر سه مدرس Xو Yو Z در سالهای 1 و 2 دوره ی تحصیلی درس گذرانده اند؟
"تمام فروشنده گانی که در هر سه شهر تهران، اصفهان و شیراز محصولات خود را فروخته اند را بدست آورید"
همانطور که در ریاضی مفهوم تقسیم بر خلاف مفهوم ضرب است در اینجا نیز تقسیم رابطه ای عکس عمل ضرب دکارتی را انجام می دهد. به تصویر زیر دقت کنید:
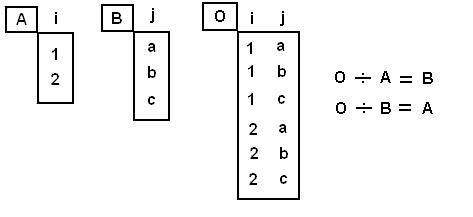
همانطوری که در تصویر فوق مشاهده می شود، مساله ساده تر از آن است که فکرش را می کنید. اگر جدول O از ضرب دکارتی دو جدول A و B بدست آمده باشد آنگاه عبارت O تقسیم بر A برابر خواهد بود با مجموعه ی B و عبارت O تقسیم بر B برابر با مجموعه ی A خواهد بود.
تقسیم را به گونه های مختلفی می توانیم در نظر بگیریم. مثلا تقسیم دقیق، تقسیم با باقیمانده و تقسیم با مقسوم علیه های محدود و معین. ولی قصد ندارم که شما را وارد تمام جزئیات کنم.
راه حل های رایج
اجازه بدین با جداول و داده های آزمایشی و sample کار را شروع کنیم.
SET NOCOUNT ON;
--Declaring tables here
CREATE TABLE Drivers
(driver_id INT IDENTITY(1, 1) PRIMARY KEY,
driver_name VARCHAR(20) NOT NULL);
CREATE TABLE Buses
(bus_id INT IDENTITY(1, 1) PRIMARY KEY,
bus_plaque VARCHAR(10) NOT NULL,
bus_color VARCHAR(20) NULL);
CREATE TABLE Trips
(trip_nbr INT IDENTITY(1, 1) PRIMARY KEY,
bus_id INT
REFERENCES Buses (bus_id),
driver_id INT
REFERENCES Drivers (driver_id),
UNIQUE (bus_id, driver_id));
--Publishing some sample data on the tables here
INSERT INTO Drivers (driver_name)
VALUES ('Driver 1'),
('Driver 2'),
('Driver 3');
INSERT INTO Buses (bus_plaque)
VALUES ('plaque 1'),
('plaque 2'),
('plaque 3');
INSERT INTO Trips (bus_id, driver_id)
VALUES (1, 1), (1, 2), (1, 3),
(2, 1), (2, 2),
(3, 1), (3,3);
ما سه جدول با نام های "اتوبوس ها"، "راننده ها" و "سفرها" داریم. که مشخصات اتوبوس در جدول اتوبوس ها و مشخصات راننده در جدول رانندها و اینکه چه راننده ای با چه اتوبوسی سفر داشته است در جدول سفرها مشخص می شود.
پرس و جوی دلخواه ما این است که تمام راننده اتوبوس هایی که با تمام اتوبوس ها سفر کرده اند را انتخاب کنیم. که در مثال ما تنها راننده شماره ی 1 هست که با هر سه اتوبوس سفر کرده است.
روش اول: شمارش
اگر تعداد اتوبوس هایی که راننده با آنها سفر کرده باشد برابر باشد با تعداد کل اتوبوس ها، مشخص می شود که با تمام آن اتوبوس ها سفر کرده است. این ساده ترین منطقی هست که میشود از آن برای حل این مساله استفاده کرد.
با این فرض که داده هایی خارج از دو جدول اتوبوس ها و رانندگان در جدول سفرها درج نمی شود query به شکل بسیار ساده ی زیر در می آید:
SELECT *
FROM Drivers D
WHERE (SELECT COUNT(*)
FROM Trips T
WHERE T.driver_id = D.driver_id) =
(SELECT COUNT(*)
FROM Buses);
روش فوق زمانی جواب صحیح به ما خواهد داد که ساختار جداول ما دارای دو وِیژگی باشند. اول اینکه در جدول سفرها، سفری با اتوبوسی خارج از جدول اتوبوس ها صورت نگرفته باشد و دوم اینکه مقادیر دو ستون کد راننده و کد اتوبوس یکتا باشد. این Unique Key باعث می شود که نتوانیم برای یک راننده دو سفر با یک اتوبوس را در نظر بگیریم.
ولی آیا اگر جداول ما دارای آن دو ویژگی نباشند Query فوق به چه شکلی در خواهد آمد؟
SELECT *
FROM Drivers D
WHERE (SELECT COUNT(DISTINCT bus_id)
FROM Trips T
WHERE T.driver_id = D.driver_id
AND bus_id IN
(SELECT bus_id
FROM Buses)) =
(SELECT COUNT(*)
FROM Buses);
می توانیم با استفاده از ماده ی GROUP BY کوئری فوق را به این شکل تبدیل کنیم:
SELECT D.driver_id, driver_name
FROM Trips T
INNER JOIN Drivers D
ON T.driver_id = D.driver_id
WHERE bus_id IN (SELECT bus_id FROM Buses)
GROUP BY D.driver_id, driver_name
HAVING COUNT(DISTINCT bus_id) =
(SELECT COUNT(*)
FROM Buses);
روش دوم:منطق بر عکس
اگر وجود نداشته باشد اتوبوسی که راننده با آن سفر نکرده باشد مطمئن می شویم که با تمام اتوبوس ها سفر کرده است. به این منطق، منطق برعکس (reverse logic) یا دوبار نقیض گیری (double negation) گفته می شود.
SELECT *
FROM Drivers D
WHERE NOT EXISTS
(SELECT *
FROM Buses B
WHERE bus_id NOT IN
(SELECT bus_id
FROM Trips T
WHERE T.driver_id = D.driver_id));
اگر تعداد اتوبوس هایی که در جدول اتوبوس ها قرار دارد و راننده با آنها سفر نکرده باشد برابر با صفر باشد می توانیم نتیجه بگیریم که راننده با تمام اتوبوس ها سفر کرده است. از نظر منطقی این معادل (equivalence) روش دوباره نقیض گیری است:
SELECT *
FROM Drivers D
WHERE (SELECT COUNT(*)
FROM Buses
WHERE bus_id NOT IN
(SELECT bus_id
FROM Trips T
WHERE D.driver_id = T.driver_id)) = 0;
روش سوم: روش اصلی
وقت آن فرا رسیده که به روش اصلی برای حل این مساله بپردازیم. چرا من این روش را روش اصلی نامیدم، بدلیل این هست که عملگر تقسیم جز عملگرهای جبری به حساب می آید و این روش تنها از عملگرهای جبری مثل تفاضل تشکیل شده است. این روش از یک فرمول تبعیت می کند:
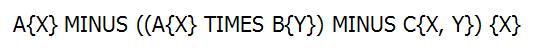
متغیر هایی که داخل آکولاد قرار دارند خصیصه نام دارند و TIMES به معنای ضرب دکارتی و MINUS به معنای تفاضل دو مجوعه است همچنین اسامی A , B , C نام های جداول هستند.اگر مقادیر ستون کد راننده را در مقادیر ستون کد اتوبوس از جدول اتوبوس ها با یکدیگر ضرب دکارتی کنیم و سپس سطرهای موجود در جدول سفرها را از نتیجه ی قبلی تفاضل کنیم تنها سطهایی باقی می مانند که در جدول سفرها موجود نبوده اند. در نتیجه می توانیم لیست افرادی که با تمام اتوبوس ها سفر نکرده اند را بدست آوریم و از لیست رانندگان تفاضل کنیم. که query مربوطه به این شکل در خواهد آمد:
;WITH TIMES (X, Y) AS
(SELECT A.driver_id, B.bus_id
FROM Drivers AS A
CROSS JOIN
Buses AS B),
MINUS_1 (X) AS
(SELECT DISTINCT X
FROM (SELECT X, Y
FROM TIMES
EXCEPT
SELECT driver_id, bus_id
FROM Trips) D(X, Y)),
MINUS_2 (X) AS
(SELECT driver_id
FROM Drivers
EXCEPT
SELECT X
FROM MINUS_1)
SELECT X AS Driver_id
FROM MINUS_2;
در query فوق قسمت عبارت جدولی MINUS_1 کمی تغییر ایجاد کردم که عمل ما دقیقا تبدیل به فرمول شود.
فرمت فشرده ی این روش، به شکل زیر است:
SELECT driver_id
FROM Drivers D
WHERE NOT EXISTS
(SELECT bus_id
FROM Buses
EXCEPT
SELECT bus_id
FROM Trips T
WHERE T.driver_id = D.driver_id);
اگر اتوبوس هایی را که راننده با آن سفر کرده است را از کل اتوبوس ها کم کنیم و سطری باقی نماند این معنا را خواهد داد که راننده با تمام اتوبوس ها سفر کرده است.
حالتی که عناصر مورد نظر به شکل یک رشته تفکیک شده هستند
حالا زمانی را تصور کنید که لیست اتوبوس ها توسط کاربر به شکل یک رشته (ی از هم تفکیک شده با یک کاراکتر) در نظر گرفته شده است. در این حالت می توانیم رشته را Split نموده (با کمک روش set-based یا ...) و با جدول JOIN کنیم یا از مفهوم pattern matching استفاده کنیم و یا اینکه از Dynamic SQL کمک بگیریم.
Pattern Matching
ویژگی pattern matching را در این مورد می توانیم به کار بگیریم با استفاده از LIKE (البته با استفاده از CHARINDEX و یا PATINDEX عمل pattern matching را نیز می توانید انجام دهید).
در اینجا ما قصد داریم تمام رانندگانی را انتخاب کنیم که با هر سه اتوبوس 1 و 3 و 2 سفر داشته اند.
DECLARE @S VARCHAR(500) = '1,3,2';
SELECT D.*
FROM Drivers D
CROSS APPLY
(SELECT COUNT(DISTINCT bus_id)
FROM Trips
WHERE driver_id = D.driver_id
AND ',' + @S + ',' LIKE '%,' + CAST(bus_id AS VARCHAR(10)) + ',%') Dt(cnt)
WHERE Dt.cnt = LEN(@S) - LEN(REPLACE(@S, ',', '')) + 1;
Splitting using number table
ابتدا یک TVF ایجاد می کنیم که تا به اندازه ی عدد ورودی اعداد متوالی ایجاد کرده و برگرداند. سپس با کمک این تابع یک جدول اعداد ایجاد می کنیم تا در تابع Splitter از آن استفاده کنیم.
--TVF for publishing and returning sequence numbers
CREATE FUNCTION dbo.Numbers (@N INT) RETURNS TABLE AS
RETURN (WITH RecCTE (nbr) AS
(SELECT 1
UNION ALL
SELECT nbr + 1 FROM RecCTE WHERE nbr < 100),
Nums (nbr) AS
(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT 1))
FROM RecCTE AS C1
CROSS APPLY
RecCTE AS C2
CROSS APPLY
RecCTE AS C3)
SELECT nbr
FROM Nums
WHERE nbr <= @N);
GO
--Creating Number Table using TVF
SELECT n.nbr
INTO Nums
FROM dbo.Numbers(10000) AS n;
GO
--TVF for Splitting the String
CREATE FUNCTION dbo.splitter (@S VARCHAR(MAX), @D CHAR(1)) RETURNS TABLE AS
RETURN (SELECT CASE WHEN CHARINDEX(@D, @S + @D, nbr) - nbr = 0 THEN ''
ELSE SUBSTRING(@S, nbr, CHARINDEX(@D, @S + @D, nbr) - nbr)
END AS Word, nbr
FROM Nums
WHERE nbr <= LEN(@S)
AND SUBSTRING(@D + @S, nbr, 1) =@D);
GO
در نهایت پس از ایجاد تابع Splitter کوئری ما به این شکل در خواهد آمد:
DECLARE @S VARCHAR(500) = '1,3,2';
--Main Query
SELECT D.driver_id, D.driver_name
FROM Trips AS T
INNER JOIN Drivers AS D
ON D.driver_id = T.driver_id
INNER JOIN dbo.Splitter(@S, ',') AS W
ON T.bus_id = W.word
GROUP BY D.driver_id, D.driver_name
HAVING COUNT(*) = (SELECT COUNT(*) FROM dbo.Splitter(@S, ','));
جدول اعداد برای هر Developer حکم یک جعبه ابزار را دارد و بهتر هست یک جدول دائمی با تعداد اعداد مورد نیاز یکبار برای همیشه ایجاد کنیم و بارها از آن استفاده کنیم.
Dynamic SQL
حتی نه به pattern matching احتیاج داریم و نه string parsing. در این مورد می توانیم با کمک Dynamic SQL این کار را انجام دهیم. در هین حالت چون Item های ما عددی هستند نیازی نداریم تا از علامت نقل قول استفاده کنیم. ولی اگر Item های رشته، از نوع رشته ای باشند نیاز داریم با یک تابع REPLACE علامت های نقل قول را اطراف ITEM ها قرار دهیم.
DECLARE @S VARCHAR(500) = '1,3,2',
@Command VARCHAR(1000);
--When the data type of items in string is VARCHAR
--SET @S='''' + REPLACE(@s, ',', ''',''') + '''';
SELECT @Command =
'SELECT D.driver_id, driver_name
FROM Trips T
INNER JOIN Drivers D
ON T.driver_id = D.driver_id
WHERE bus_id IN (' + @S + ')
GROUP BY D.driver_id, driver_name
HAVING COUNT(DISTINCT bus_id) =
(SELECT COUNT(*)
FROM Buses);';
EXECUTE(@Command);
خلاصه ی مطالب
در این مقاله سعی شد به راه حل های رایجی که برای حل این مساله وجود دارند اشاره شود. و یک ایده ی جدیدی برای حالتی که لیست مقسوم علیه ها به شکل یک رشته ی تفکیک شده با کاراکتر کاما در نظر گرفته شده است ارائه داده شد.
البته زمانی که تعداد مقادیر جدول مقسوم علیه مشخص و محدود باشند از تکنیک های مختلفی از جمله Pivoting Data و گرفتن اشتراک (با کمک INTERSECT یا روشهای متعدد جایگزین) می توانیم بهره مند شویم.