|
همانطور که در این مقاله اشاره شد Query ها را از دو طریق کلی می توانیم خلق کنیم. جبر و گزاره. عملگرهایی چون Except و Intersect و Union جز عملگرهای جبری هستند. در این مقاله به راه حل هایی اشاره خواهد شد که اشتراک دو مجموعه را دقیقا همانطوری که به صورت علمی تعریف شده است پیاده سازی می کنند.
البته در زبان SQL عملگرهایی چون EXCEPT ALL و INTERSECT ALL و UNION ALL نیز وجود دارند. ولی در SQL Server تنها UNION ALL پیاده سازی شده است.
عملگر UNION به عنوان عملگر اولیه شناخته می شود و با کمک آن می توانیم اشتراک و تفاضل دو مجموعه را بدست آوریم. موارد استفاده از عملگرهای INTERSECT و EXCEPT بستگی به میزان دانش و خلاقیتی که بدست آورده اید دارد. و هیچ اجباری به استفاده از آنها نیست ولی با کمک آنها می توانیم Query هایی را خلق کنیم که بسیار با سلیقه (elegant) و جمع و جور (compact) طراحی شده اند.
اشتراک دو مجموعه
نمودار ون (Venn Diagram):
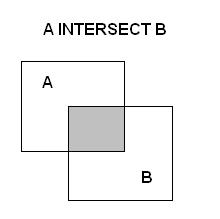
تعریف اشتراک: اشتراک دو مجموعه ی A و B مجموعه ای خواهد بود که اعضای آن در هر دو مجموعه وجود دارند. و با نماد های ریاضی داریم:
A INTERSECT B = {X | X element of B set AND X element of A set}
بطور مثال فرض کنید یک View داریم که لیست دانشجویان ممتاز را در خود جای داده است و View دیگر لیست دانشجویانی که مشروط شده اند را نمایش می دهد. حالا اگر بخواهیم لیست دانشجویانی را بدست آوریم که در دوران تحصیلی خود هم شاگرد ممتاز بوده اند و هم مشروط شده اند اشتراک دو View را می گیریم. (البته بعید می دانم که سطری برگردانده شود)
کدهایی که در ادامه قرار خواهند گرفت بر روی بانک Northwind صورت می گیرند. این بانک را می توانید از این لینک دانلود کنید.
فرض کنید می خوهیم اشتراک بین سطرهای دو جدول مشتری و کارمندان را بر اساس سه ستون کشور، منطقه و شهر بگیریم.
SELECT Country, Region, City
FROM Customers
INTERSECT
SELECT Country, Region, City
FROM Employees;
انواع روش های جایگزین INTERSECT:
1. CROSS APPLY table operator (قابل استفاده در SQL Server 2005 و بالاتر)
2. UNION ALL set operator
3. Composite INNER JOIN table operator
4. IN predicate
5. EXISTS predicate
6. EXCEPT set operator (قابل استفاده در SQL Server 2005 و بالاتر)
روش اول
تا رسیدن به تسلط در استفاده از یک ابزار جدید نیاز به تمرین بسیاری دارد. بنده تا امروز استفاده ی چندانی از این عملگر نکرده ام و هنوز برایم تازگی دارد. در مواقعی که جدول مشتق شده ی (Derived table) سمت راست عملگر وابسته (Correlated) به جدول سمت چپ عملگر باشد از APPLY استفاده می شود.
از این عملگر در بدست آوردن اشتراک سطرهای دو جدول می توانیم استفاده کنیم (همانطوری که در مقاله ی قبلی در تفاضل جدول استفاده کردیم).
از تابع COALESCE استفاده کردیم چون نیاز به مکانیزمی داریم که با یک دستور تمام مقادیر از جمله NULL ها را با یکدیگر مقایسه کنیم.
--CROSS APPLY
SELECT DISTINCT E.Country, E.Region, E.City
FROM Employees E
CROSS APPLY
(SELECT 1
FROM Customers C
WHERE COALESCE(C.Country, '1') = COALESCE(E.Country, '1')
AND COALESCE(C.Region, '1') = COALESCE(E.Region, '1')
AND COALESCE(C.City, '1') = COALESCE(E.City, '1')) D(i);
روش دوم
اگر دو جدول را به طوری که داده های تکراری دو بار در نظر گرفته شوند اجتماع کنیم (یعنی UNION ALL) سپس گروه بندی کنیم آن وقت گروههایی که دو سطر دارند به این معنا هستند که در هر دو جدول وجود دارند.
--UNION ALL
SELECT D.Country, D.Region, D.City
FROM (SELECT DISTINCT Country, Region, City
FROM Customers
UNION ALL
SELECT DISTINCT Country, Region, City
FROM Employees) AS D
GROUP BY D.Country, D.Region, D.City
HAVING COUNT(*) = 2;
روش سوم
اکثر اوقات شکل استفاده از JOIN ساده است یعنی تنها برابری دو ستون با یکدیگر ارزیابی می شود ولی در اینجا چون سه ستون بایستی با همدیگر مقایسه شوند شرط اتصال از ترکیب چند شرط ایجاد شده است. به اینگونه Join ها اتصال ترکیبی (Composite Join) گفته می شود.
--JOIN
SELECT DISTINCT C.Country, C.Region, C.City
FROM Customers AS C
JOIN Employees AS E
ON COALESCE(C.Country, '1') = COALESCE(E.Country, '1')
AND COALESCE(C.Region, '1') = COALESCE(E.Region, '1')
AND COALESCE(C.City, '1') = COALESCE(E.City, '1');
روش چهارم
در اینجا طبق روش موجود در مقاله ی قبلی عمل شده است منتهی به جای NOT IN از IN استفاده کرده ایم.
--IN
SELECT DISTINCT Country, Region, City
FROM Customers AS C
WHERE COALESCE(C.Country, '1') IN
(SELECT COALESCE(E.Country, '1')
FROM Employees AS E
WHERE COALESCE(C.Region, '1') = COALESCE(E.Region, '1')
AND COALESCE(C.City, '1') = COALESCE(E.City, '1'));
روش پنجم
این روش هم دقیقا مشابه روش معرفی شده در مقاله ی قبلی است ولی به جای NOT EXISTS از EXISTS به تنهایی استفاده کرده ایم.
--EXISTS
SELECT DISTINCT Country, Region, City
FROM Customers AS C
WHERE EXISTS
(SELECT *
FROM Employees AS E
WHERE COALESCE(C.Country, '1') = COALESCE(E.Country, '1')
AND COALESCE(C.Region, '1') = COALESCE(E.Region, '1')
AND COALESCE(C.City, '1') = COALESCE(E.City, '1'));
روش ششم
اشتراک یک عملگر اولیه نیست. و آن را می توانیم با تفاضل بدست آوریم.
A INTERSECT B = A EXCEPT (A EXCEPT B)
A INTERSECT B = B EXCEPT (B EXCEPT A)
A INTERSECT B <=> B INTERSECT A
--EXCEPT
SELECT Country, Region, City
FROM Customers
EXCEPT (SELECT Country, Region, City
FROM Customers
EXCEPT
SELECT Country, Region, City
FROM Employees);
در خاتمه خوشحال می شوم فردی با روشی غیر از روشهای ذکر شده من را شگفت زده کند.
|